How does S.M.A.R.T. function of hard disks Work?Some time ago an article published about hard disk reliability and the failure prediction function of hard disks. We can think that this function is not working or not too reliable because it is not able to predict disk failure in all cases. It may be partially true - but the situation is not too simple. Now, we want to make things clear. First, we examine what is S.M.A.R.T. and how it works. Advanced users may skip some paragraphs. S.M.A.R.T.S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology) is designed by IBM. It was created to monitor the disk status by using various methods and devices (sensors). A single ATA hard disk may have up to 30 such measured values, which are called attributes. Some of them directly or indirectly affect hard disk health status and others give statistical information. Today all modern IDE/Serial ATA/SCSI hard disks have S.M.A.R.T. feature. It is not really a standard - so the meaning of the attributes may be different from manufacturer to manufacturer. In this article, we discuss ATA (IDE and Serial ATA) hard disks only. SCSI hard disks work differently: the failure predicition data is standard and there are strict rules about the sensors and algorithms. For example, the difference between real temperature and the result measured by the sensor should be less than +/- 3 Celsius degrees. Many attributes are used by all manufacturers and they are used in the same (or near same) way. That's why for example it is possible to detect the temperature and the total power on time of many hard disks. Newer applications are able to detect, process and display these information. According the S.M.A.R.T. specifications, when a problem is detected (failure predicted), the hard disk should work for at least 24 hours to perform the data backup. But in many cases this time is not enough - that's why it is important to recognize problems and prepare before it's too late. S.M.A.R.T. in actionThe current status of the hard disk are constantly examined by many sensors. The measured values are then processed by some algorithms and the corresponding attributes are modified according the results. A single S.M.A.R.T. attribute has the following fields:
Note: software may display more information based on these fields (for example, the status of an attribute, which can be "OK" or "Always OK" etc.) and may give help in evaluation or management of the attributes.
An attribute is correct, when the Value is greater than or equal with the Threshold. If this is not true for a critical attribute, failure is predicted, the hard disk is considered bad and it should be replaced immediately (the attribute determines the problem). Manufacturers/vendors replace the hard disk in the terms of warranty. The S.M.A.R.T. function in modern motherboard BIOSes warns the user at this point before booting the operating system. If the Threshold is 0 for any attribute, that attribute is not able to predict failure (because the Value cannot be less than 0). Mathematically, one attribute is perfect if the following inequality is TRUE (you may skip this paragraph if you hate maths): Where:
This method has some disadvantages. The A, B, C, values (or the f function) are not defined exactly (these may vary from model to model even on two hard disks from the same manufacturer). Other disadvantage is that the attributes are evaluated independently, the relationship between them is ignored. The problems with S.M.A.R.T.The model described above has many weak points. Because of these problems, in most cases failure prediction is not working at all. The major problems are: #1 Incorrect thresholdsMost problems with S.M.A.R.T. (lack of failure prediction) are caused by incorrectly selected Thresholds. Because of this, the hard disk attributes have no chance to reach the thresholds - usually they fail (become useless) before reaching this point. In such cases, S.M.A.R.T. really does not predict the failure. In practical, we can find non realistic threshold values. For example, on most hard disks, many thousands of bad (not readable and writable) sectors required (according to the size of the spare area) before S.M.A.R.T. shows the problem. It does not seem to be a big problem because 1000 such bad sector takes "just" 512000 bytes of data (and this does not mean capacity loss because of using the spare area instead), but it may be important how these bad sectors born, where they are located on the surface and what is the bad sector increase rate. In most cases, problems can be detected long time before an attribute value reaches its threshold. For example, a head problem which can make many thousands of sectors unusable (bad), can cause bigger parts of the disk surface unreadable - preventing the recovery of data from this disk area. Also analysing a such problematic area and saving the data to spare area may need lots of time (even hours), and it is possible that the operation is not completed without errors. During this process, the operating system usually stops responding, so a problematic hard disk may cause complete system instability.
We can discuss about improperly selected threshold values also. Some hard disk manufacturers may define 60-70 years or even more for a hard disk total lifetime when the corresponding attribute is examined. It is really interesting - because manufacturers usually define the designed lifetime in 5 years in product manuals. Moreover, S.M.A.R.T. will not alert when the end of the lifetime is reached because this attribute is usually not a critical one.
Moreover, the threshold value is 0 for many critical attributes. Because the Value cannot be decreased below 0, these attributes will never indicate any sign of failure - even if they "want" to do this. So S.M.A.R.T. will never alert.
Sometimes very important attributes are not marked as "critical". It means that hard disk monitoring applications and the BIOS S.M.A.R.T. feature do not examine these attributes at all. #2 Wrong evaluation methodMost applications use the vendor-specific method described above to calculate and display the health of the disk. The result is that most hard disks look much better than their real status. Hard disk manufacturers may choose thresholds or algorithms to show their hard disks better than an other hard disk from an other manufacturer also. This may mislead applications and users as well. Software developers just use the manufacturer-dependent evaluation method and they do not do anything about detecting the real health status of the disks. Because of this, it is possible that the user use a hard disk monitoring application but the hard disk fail before showing any sign of problems or even a decrease in condition. Such applications may display 10-20 years or more as estimated remaining lifetime - which is at least questionable. #3 Weight of attributesDifferent attributes affect disk health differently. Some attributes (for example, 10 - spin retry count) are very critical. A small change in this attribute may indicate a serious problem, for example bad motor or bearing - but maybe a weak power supply can cause this problem also. For such attributes, manufacturers often use a high threshold value, so they can be reached relatively easily. But because of the selection of the threshold and the f function described above in (1) inequality, some problems may be completely ignored. So users will not notice any changes of the critical attributes. An other problem is that the relationship between the attributes is often ignored. It is possible that two or more attribute values almost reach their thresholds - but failure is not predicted because no value reached the threshold level. #4 Lack of feedbackWithout using a proper software which is able to read S.M.A.R.T. information, the user does not notice any problems with the hard disk, just when it's too late. If the number of bad sectors increase slowly (the hard disk founds some new problematic sectors and tests them and reallocates them), the user may not notice anything, especially if only the screensaver is running. But during re-allocation procedure, the operating system seems to be frozen (not responding) and users may reset or power off the computer at this time. Such power loss does not help the hard disk too much in the recovery process (it will be re-started at a later time). #5 Temperature, sensor problemsWithout using software, the user may not notice high hard disk temperature also. Both CPU and newer VGA cards have protection (emergency shutdown) against high temperatures but hard disks have no such protection. Even worse, hard disks are much more sensitive to high temperatures than any other component inside the computer case. That's why most manufacturers limit the maximum operating temperature in 50-55 Celsius degrees. Most BIOSes have support to examine the power supply voltage, fan speeds, CPU temperature etc. But it is not possible to examine hard disk temperature from BIOS. The BIOS S.M.A.R.T. function does not alert if the hard disk temperature is too high. So it is possible that the hard disk is operating in a very hot environment. But it is important to know that many hard disk temperature sensors are not too accurate (sometimes the difference between detected and real temperature can be 8-10 Celsius degrees or even more). It is recommended to use an external device (for example an infrared thermometer) to measure the hard disk temperature and configure the difference between the measured and displayed values (calibration). So the software then displays the correct (adjusted) temperature value (if this feature is supported). It is also recommended to examine the temperature when the hard disk is idle and when it is operating for a longer time.
#6 Incorrect driversWe may find many incorrect drivers for hard disk controllers. By using such drivers, one or more hard disks do not provide S.M.A.R.T. information connected to such controllers (or motherboards). This is usually independent from the used software because applications generally use the same method to access hard disk and detect information about it. It is possible that two hard disk provide 100% same information (usually the details of the first or PRIMARY MASTER hard disk). Software may filter this and display real (but partial) information but it is recommended to verify that the details are correct (for example, no hard disk serial number is displayed 2 or more times). Usually, the drivers support only a limited range of hard disk commands. That's why some features do not work in all cases (for example, acoustic management), even if the disk supports it. It is recommended to examine if manufacturer has updated, fixed driver packages or firmware updates. These may improve the situation. If a controller has RAID and non-RAID drivers, it is important to use the correct (non-RAID if no RAID array used) drivers. Using the other package may limit some features and usually temperature, health status of the disk(s) will not be displayed. Many motherboards or hard disk controllers do not have 100% correct drivers for Vista. This can also prevent detection of detailed hard disk information and failure prediction under the new operating system. #7 Incorrect hardware or incorrect dataThis is the extension of the previous problem #6. Some hard disk controllers or motherboards do not provide S.M.A.R.T. threshold values at all - or all threshold values are 0. Hard disks connected to such controllers will not show any sign of failure because the attribute values are not able to decrease below 0. Applications may also show the hard disk condition "excellent" because the Values are far from the thresholds.
It is also possible that the information provided by the hard disk controller is not complete. This does not affect the hard disk failure prediction status but some information detected and displayed may not be correct. Fortunately this does not affect the temperature and the hard disk health also. Newer applications verify the ATA signature and checksum values (described on page 116 of "AT Attachment - 8 ATA/ATAPI Command Set") and display a warning if these values are not correct.
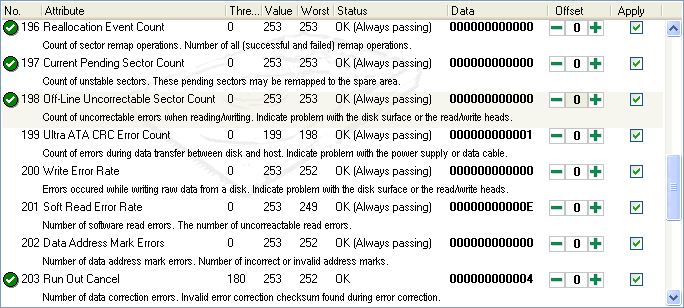
Bad sectors?Users often ask about what is a "bad sector", how they born and what they can do to fix these. Users are confused because verifying the disk surface with software (for example by using Windows Scandisk) does not report any problems or bad sectors. S.M.A.R.T. is constantly analysing the disk surface during normal operations. If it finds a problematic area (one or more sectors where the data is hard to read or write), it tries to read the data and copy it to the spare area. The original location is then (internally) marked as bad and all further read/write operations pointing to the original location is then redirected to the spare area. When the operation is completed, the original (bad) area is not accessible by software any more. Even re-install or many complete format operations will not show problems because the original bad area is not used any more. That's why software (for example Windows' Scandisk) will not found problematic sectors. Only the hardware security erase function will access this area (clearing these sectors also). That's why for example DOS "format" command will never show bad sectors on most modern hard disks because of S.M.A.R.T. (except if the spare area is full but it is really hard to find a such hard disk). Reallocation of the sectors may be completed with or without some errors (hard disks are working much better now compared to older models). But the reallocation procedure may cause system instability if it takes too much time. The user should not notice anything about the steps described above - just when the number of bad sectors is high enough (the threshold is reached) and then S.M.A.R.T. predicts a possible failure. SolutionA hard disk failure without any signs before the catastrophe is extremely rare, except if drive fall down, or if high power (bias) or natural disaster cause problem. But these situations cannot be predicted by S.M.A.R.T. of course. Usually some bad sectors born, their number is slowly increasing (maybe weeks can elapse without any sign of new problems). In other cases, high temperature and/or few but really critical problems can cause the death of a drive. It is also very common that the combined effect of two or more attributes indicate different problems. For example, if the hard disk motor is not able spin up easily (it needs some retries) or the disk spins up too slowly, it may indicate a possible motor or bearing problem. Such problems have written traces in the corresponding S.M.A.R.T. attributes. So all (even very small) changes can be detected. It is important to detect these signs long time before they can lead to failure. It is recommended to completely discard the whole model described above and ignore the incorrectly choosen (or missing) threshold values and evaluate only the raw measured data numbers, to detect the real amount of different problems about the hard disks. It is advisable to examine the connection between different attributes also. This way we'll have correct picture about the real status and we can prepare and even avoid data loss. It is also recommended to select how we want to evaluate the hard disk status, depending on the real usage and "stress" of a hard disk. For example, in case of a server, notebook or a hard disk with critical information, the smallest problem can be dangerous, so any problem (even small one) should be noticed. Some applications may offer such different evaluation methods for different uses of hard disks and they may give textual description about the current situation and tips to improve the condition. It is a nice function if the software can make passive alarms (send e-mail, play sound or shut down the computer) but it may be better if the application is able to actively prevent data loss, for example by performing an automatic backup operation if a new problem is found. Hard Disk Sentinel application was developed considering these requirements. During the development, the S.M.A.R.T. information of many (failed, not working) hard disks were examined from many different manufacturers. The evaluation methods were designed based on the collected information. It is important to say that the "traditional" S.M.A.R.T. did not predicted failure for most of these hard disks. ExampleWe received a not working hard disk for data recovery with the following S.M.A.R.T. attributes:
The BIOS S.M.A.R.T. function did not show any problems. According to the table, the Values (100 and above) are very far from the corresponding Threshold limits. Most of them (Value = 100) are still on the theoretical maximum. If we would use the traditional evaluation method (by checking the values and thresholds), the hard disk condition seems to be perfect. Values under 100 are caused by the age and usage of the drive. But the total power on time of this hard disk is only 5313 (0x14C1) hours (the manufacturer defined he total lifetime correctly: the total lifetime is approximately 4.7 years, using the disk 24 hours every day (5313/0.13)/24/365 = 4.665 years). So the drive is not too old. In contrast, if we use Hard Disk Sentinel and select the strict evaluation method (because this hard disk is a 2.5" one, used in a notebook), we will get a completely different result. During the evaluation, the software examines the important attributes (even if they are not marked as "critical" by the manufacturer). The health of the hard disk (checking the Data field of attributes 5, 196 and 197): 100 x (100 - 10x6) x (100 - 30) x (100 - 4x4) = 23.52 % According to this number, the health is disquieting. By default, this software would alert the user if the health value is as low as this number. By selecting the correct evaluation method and the correct alert levels, it is possible to predict failure long before the catastrophe. The owner of this hard disk could prevent data loss if he'd install this software before. A low health value alone does not neccessary mean that the hard disk will surely die in the near future (to verify this, a complete (hardware) examination is required), but there is a real chance for failure. The problem of the hard disk described above can not be easily detected but as we can see, there were some signs in the S.M.A.R.T. attributes. Other hard disks with other problems may work for a long time, months or years (even if they have lower health value). Problems caused by a short period (for example, too hot environment or an incorrect power supply) will not disappear. But after fixing the reasons of such problems (using a heatsink, fan or replacing the power supply), the hard disk lifetime can be extended. Anyway, it is recommended to examine the status of these hard disks constantly or regulary and to use them as secondary data storage only. Users should make sure that their important and valuable files are stored on an other hard disk also (with a higher "health" value). You may use, redistribute this article or any part of it if you add a link also to the original source. Back to Hard Disk Sentinel homepage BibliographyInformation technology - AT Attachment 8 - ATA/ATAPI Command Set (ATA8-ACS) (Revision 3f December 11, 2006) Page views: 1324 |