SSD case: SSD health decrease by wearout
With many solid state drives (SSDs) we can experience the following:
the reported health of the SSD decreases from time-to-time by "no reason"
the SSD shows no problems: Disk menu -> Short self test, Extended self test, Surface test -> Read test functions show no errors
the SSD may show degraded performance especially on lower health (50% or below)
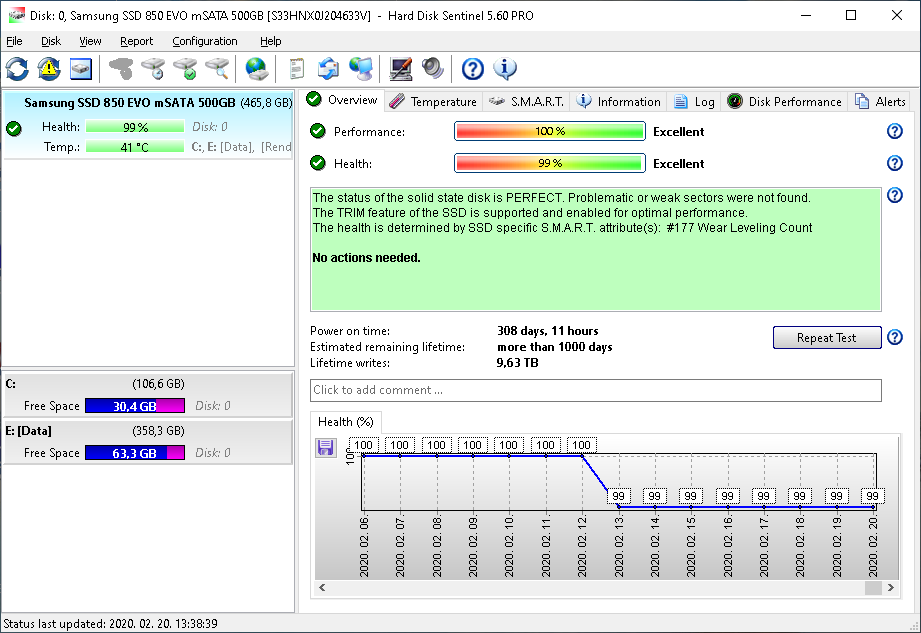
There is a frequent question: why the health is not 100% if the SSD is reported as PERFECT in the text description? Usually the text description on the Overview page contains the answer too: The health is determined by SSD specific S.M.A.R.T. attribute(s): ...
SSD functionality in general
Generally the memory cells in solid state devices experience wear during each write operations and each memory cells tolerate only a limited (finite) number of overwrite passes. (This value is usually smaller and smaller as bits stored in each cells increase: SLC->MLC->TLC->QLC). Most solid state disks (SSD devices) report the overall health of the memory cells by various attributes.
If there are no further problems found (for example no bad sectors found on the SSD, Hard Disk Sentinel reads such attribute(s) determining the complete health of the solid state disk. For example the text description area may show the following details:
The status of the solid state disk is PERFECT. Problematic or weak sectors were not found. |
As displayed, no problems found (so the SSD works without problems, tests should show no errors) but the mentioned attribute determines the overall health of the device. On the S.M.A.R.T. page, it is possible to examine how the affected attribute may changed over time.
This generic health value is calculated by the SSD itself in a way defined by the manufacturer (depending on number of program/erase cycles, amount of written data and so). It is completely independent from Hard Disk Sentinel and any software, actual OS / Windows version, restart and so: as the amount of written data increases, the health of the SSD should slowly and surely decreases.
Depending on the manufacturer and model of the SSD, there are different attributes which can determine the generic health of the SSD (usually only one of them present on the S.M.A.R.T. page):
#169 Remaining Life Percentage
#173 Media Wearout Indicator
#177 Wear Leveling Count
#202 Percentage Of The Rated Lifetime Used
#231 SSD Life Left
Percentage used endurance indicator (for SAS SSDs)
Available Spare Percent, Percentage Used (for NVMe M.2 SSDs)
The benefits of SSD health decrease
Even if sounds weird, the health decrease is not bad, exactly the opposite. The health decrease can help us to
be prepared for a planned replacement when the health goes too low (for example below 50% or even earlier especially in a mission-critical environment).
be notified about possible high amount of writes caused by some applications, Windows updates or similar which can cause degradation.
try to minimise the amount of writes to extend the lifetime of the SSD.
Usually manufacturers define a Terabytes Written (TBW) value for SSDs, which is typically around 100-200 Terabytes (100000-200000 Gigabytes). If the health of the SSD decreases due to excessive amount of writes and the SSD fails, the manufacturer may refuse replacement if the amount of written data is higher than this value. Refer to the manual/specifications of your particular SSD about the actual TBW related to that model.
Recommendations
As health decrease caused by wearout can't be fixed / repaired (as we can't replace memory cells of the SSD) we can only try to extend the lifetime by minimising the amount of data written to make the degradation slower. Observe the Health % and the Lifetime writes value (showing the total amount of data written) values on the Overview page to be notified about the current status of the device.
Different SSDs may be affected differently - as some SSDs can show very frequent decrease of health, the health can even go down every some days:
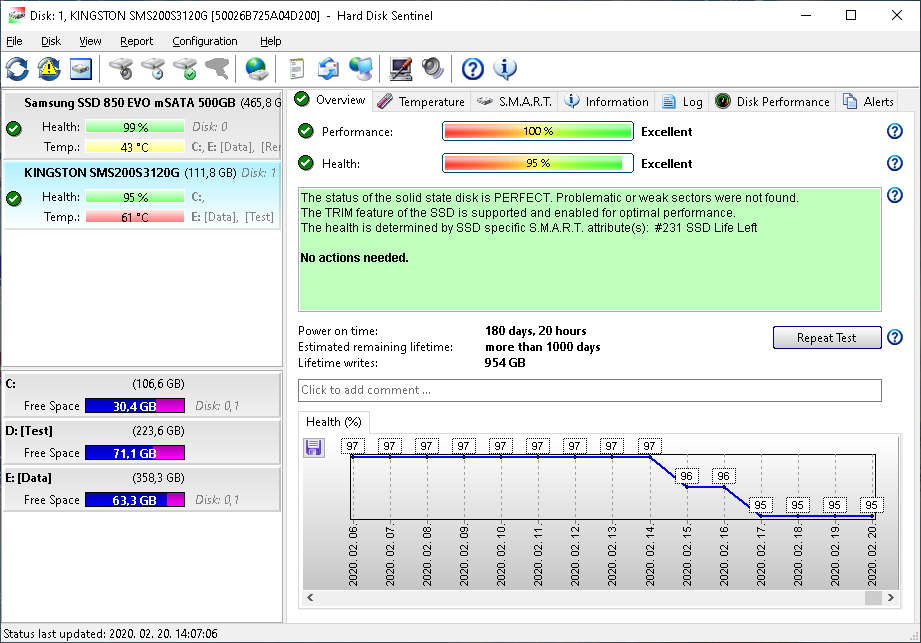
In some cases, a Windows (re)installation, major update may cause high amount of data written (eg. 10-30 GBytes written) and as a result, the health may go down immediately with a percent, for example from 100 to 99%. This is normal and there is no need to worry until the health is still high (above 50%).
Custom health threshold for the SSD
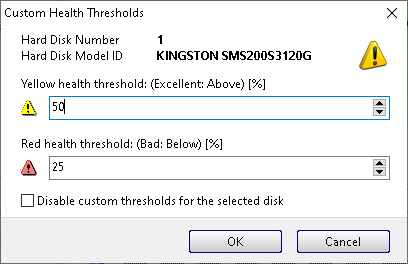
To prevent "low-health" alert triggered due to wearout and specify a custom health threshold level for the SSD: double click on the Health bar on the Overview page. Then it is possible to specify custom health warning (yellow level) and alert (red level) thresholds for the device to prevent triggering alerts (for example if the global health alerts set to very strict values, eg. 90% on the Configuration -> Thresholds/Tray Icon page).
Similarly, it is possible to specify custom temperature thresholds on the Temperature page, in the upper right corner by the "Set custom temperature thresholds" link. This may be important for some SSDs, especially NVMe M.2 SSDs which can work (and tolerate) higher temperature ranges, for example 60-70 Celsius (or even higher) too. Any device may have custom health / temperature thresholds, so it is possible to define different, independent health / temperature thresholds even for all hard disks / SSDs in Hard Disk Sentinel.
Monitoring the status of all SSDs are very important to be notified about possible degradations, new problems related to normal wearout caused by usage (writes) or even bad sectors which may affect SSDs and hard disks too and cause unreadable files/folders, unbootable system, data corruption or data loss.